Cassandra reúne las tecnologías de sistemas distribuidos de Dynamo, al ser eventualmente consistente, y el modelo de datos de BigTable de Google, proporcionando un modelo de datos basado en ColumnFamily.
De este modo, los datos se organizan mediante un sistema “Clave-Valor” enriquecido, lo que ofrece una visión totalmente diferente a lo que acostumbrado a ver en los sistemas relacionales.
Modelo de datos
- Colum: El elemento básico del sistema, es una estructura con tres campos que contienen: el nombre de la columna, el valor de la columna y una marca de tiempo.
Un ejemplo concreto representado en JSON sería el siguiente:
{
name: "userName",
value: "Dave Jones",
timestamp: 125555555
}
La clave y el valor se almacenan como datos binarios.
El timestamp indica la última vez que se actualizó la column.
- SuperColum: Elemento compuesto de varias columnas ( colums).
Su representación en JSON:
{
name: "address",
value: {
city: {name: "city", value: "San Francisco", timestamp: 125555555},
street: {name: "street", value: "555 Union Street", timestamp: 125555555},
zip: {name: "zipcode", value: "94105", timestamp: 125555555},
}
}
Cassandra utiliza como clave el nombre de la column:
city: {name: "city", ...
- Colum Family: Sería equivalente a una tabla en un esquema de datos relacional. Se trata de un contenedor para una colección ordenada de Colums.
Ejemplo:
UserProfile = {
name: "user profile",
Dave Jones: {
email: {name: "email", value: "dave@email.com", timestamp: 125555555},
userName: {name: "userName", value: "Dave", timestamp: 125555555}
},
Paul Simon: {
email: {name: "email", value: "paul@email.com", timestamp: 125555555},
phone: {name: "phone", value: "4155551212", timestamp: 125555555},
userName: {name: "userName", value: "Paul", timestamp: 125555555}
}
}
Compuesta de varias filas que serían la clave (pk) , concepto similar al de clave en un sistema relacional:
UserProfile = {
Dave Jones: {
...
},
Paul Simon: {
...
}
}
Cada una de ellas compuesta de columnas:
Paul Simon: {
email: {name: "email", value: "paul@email.com", timestamp: 125555555},
phone: {name: "phone", value: "4155551212", timestamp: 125555555},
userName: {name: "userName", value: "Paul", timestamp: 125555555}
}
- Key Space: Es el contenedor para las Colums Family, más o menos el equivalente a una base de datos en el modelo relacional. Es una colección ordenada de Columns Family.
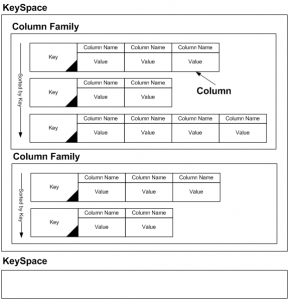

- Cluster: Conjunto de máquinas o nodos que ejecutan Apache Cassandra y proporcionan al sistema escalabilidad horizontal, de manera transparente para el cliente.
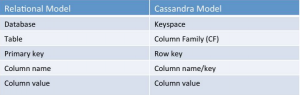
COMPARACIÓN ENTRE BD RELACIONAL Y CASSANDRA
Insercción de datos en Cassandra
Cuando vamos a almacenar los datos en un cluster, en Cassandra vamos a almacenarlos ya ordenados. Lo más normal es crear una familia de columnas (column family).Como hemos podido apreciar en la imagen anterior en blanco y negro, aparecían las column family ordenadas por la clave (Row key). Al tener los datos ya ordenados, se aumentará el rendimiento respecto a no tenerlos ordenados (a la hora de realizar consultas). Todas las claves se ordenarán dependiendo el comparador definido previamente. Lo normal es tener ordenadas las column y las row por el nombre. Cassandra nos proporciona una serie de comparadores para definir el orden:
- BytesType
- UTF8Type
- LexicalUUIDType
- TimeUUIDType
- AsciiType
- LongType
Un ejemplo sería el siguiente:
create column family users with comparator = UTF8Type and
column_metadata = [{column_name: userName, validation_class:UTF8Type},
{column_name: email, validation_class:UTF8Type}];
Si no tuviéramos definidos los comparadores:
UserContact = {
name: "user profile",
Pete Samsome: {
...
},
Dave Jones: {
paulAddress: {
name: "paulaAddress",
value: {
street: ...,
city: ... ,
zip: ...
}
},
johnAddress: {
name: "johnAddress",
value: {
street: {name: "street", value: "555 Union Street", timestamp: 125555555},
city: {name: "city", value: "San Francisco", timestamp: 125555555},
zip: {name: "zipcode", value: "94105", timestamp: 125555555}
}
}
}
}
Pero si los definimos, ya que nos da la oportunidad Cassandra:
UserContact = {
name: "user profile",
Dave Jones: {
johnAddress: {
name: "johnAddress",
value: {
city: {name: "city", value: "San Francisco", timestamp: 125555555},
street: {name: "street", value: "555 Union Street", timestamp: 125555555},
zip: {name: "zipcode", value: "94105", timestamp: 125555555}
}
},
paulAddress: {
name: "paulaAddress",
value: {
city: ... ,
street: ...,
zip: ...
}
}
},
Pete Samsome: {
...
}
}
Lenguaje de Consultas
SQL es un lenguaje de consultas ampliamente conocido, por lo que resulta muy interesante que una base de datos NoSQL permita manejar una sintaxis SQL-like para evitar tener que aprender otro lenguaje (véase el caso de MongoDB). Cassandra nos ofrece su propio lenguaje SQL-like: CQL (Cassandra Query Language).
CQL no tiene nada que ver con SQL, tan solo se le parece, ayudando así a los que vienen del mundo relacional. Exige un cambio de mentalidad: NO HAY RELACIONES. Incluye sintaxis SELECT, INSERT, UPDATE, DELETE, TRUNCATE, CREATE, DROP,…
Veamos algunos ejemplos de este lenguaje de consultas:
SELECT

INSERT
 UPDATE
UPDATE

 DELETE
DELETE


CREATE KEYSPACE

CREATE COLUMNFAMILY

CREATE INDEX

